Free Range LLMs: What Are They, Where Are They, and Can We Trust Them?


Table of Contents
Table of Contents
⚠️ This article discusses uncensored "free range" AI models for defensive cybersecurity purposes only. The goal is to help defenders understand and protect against threats, not enable other kinds of nefarious, unethical, or just plain awful activities using generative AI.
Introduction 🚀
The large language models (LLMs or GenAI) provided by the major “foundational” vendors such as OpenAI, Anthropic and Google,etc., are extremely powerful. I personally use them all the time. However, the downside of using them is that they are controlled by the company behind them and can change at any time according to the whims of the vendor.
Also, for legal and business reasons, these providers have to put in a lot of guardrails and controls to ensure that their models are not used for nefarious purposes, or that they do not output racist or other awful content –which they would absolutely do without any controls.
However, these guardrails can also limit the utility of the models in certain use cases, especially when it comes to blue team and defensive needs, such as writing “attacking” test code or understanding the risk of a particular vulnerability or exploit. Models from top-tier vendors will flatly refuse to do these things, leaving defenders at a bit of a disadvantage.
See previous posts in this series for more details:
- WhiteRabbitNeo: An Uncensored, Open Source AI Model for Red & Blue Team Cybersecurity
- How to Run WhiteRabbitNeo Models Locally
Free Range LLMs 🦅
What’s a “Free Range LLM”?
It’s something I’m calling an LLM that does not have any, or at least many, guardrails or controls, or it may be an open source model that has had the existing guardrails removed. They can be used for a wider variety of purposes, including, in the purview of TAICO, blue team and defense use cases. Basically, models that will output the code that I ask it to output, without politely refusing to do so.
What I’m calling “free range” others might call “uncensored” or “unfiltered”. It’s kind of a funny take on the idea of “free range” chickens and uncensored models. 😊
The TAICO Use Case - Is Having a Good Offence an Advantage to Having a Good Defence? 🛡️
From a TAICO viewpoint, we’re looking for models that can help us from a red, blue, purple or other cybersecurity team perspective, where we might need to write test attack code or understand the risk of a particular vulnerability or exploit. Most of the big LLMs will refuse to help in these areas, so we have to look elsewhere. We are working to answer the question of whether having a good offence is an advantage to having a good defence.
Examples of Free Range LLMs 🔓
First - Caveats ⚠️
- It’s important to understand that if we’re looking for uncensored or “free range” models, we’re now entering uncharted waters…and there be dragons.
Anyone can take an existing open source model, remove the guardrails and publish it on huggingface or elsewhere. In the end, we don’t really know how trustworthy these models are. We may trust OpenAI or Anthropic more than the average person on the internet because they have some legal and business requirements that they have to meet in terms of liability and trust. But open source models don’t have to meet those requirements, they don’t necessarily have business to lose, and they don’t have to worry about the PR hit if their model is used for nefarious purposes.
-
Running a model is a lot like running software. You have to be careful who you trust.
-
Some people who make uncensored models do so for illegitimate, unethical or potentially disturbing and offensive reasons.
That is not our aim here, and you would have to question the motives of the people who make these models. Some may be well intentioned but others may not be. If you are looking for an uncensored “free range” model, you need to do your own due diligence and ask questions about their motives and goals for using the model.
- Uncensored “free range” models can absolutely say–and do–terrible things.
Examples 📚
So with that in mind, let’s look at some examples, but again, don’t just run anything blindly. Note that these are NOT endorsements, just examples of what is out there, and how one might go about finding them and questioning their trustworthiness.
- WhiteRabbitNeo - These are the models that started this whole thing here at TAICO.
- Cognitive Computations - This seems to be a series of models created by Eric Hartford but it’s not clear. There’s a video that discusses the models a bit.
There are also some lists of uncensored models out there:
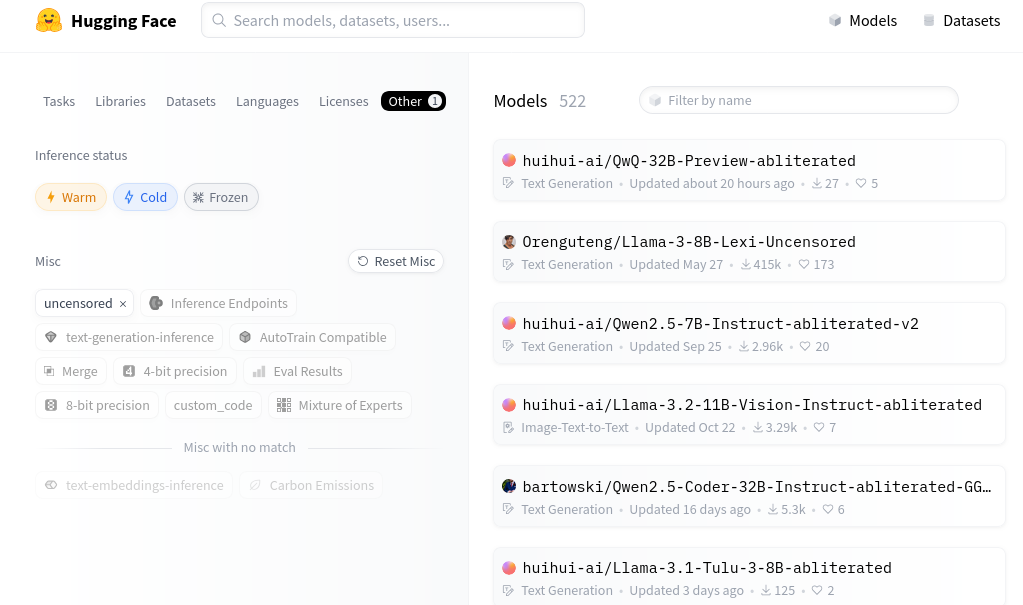
- In Hugging Face you can search for “uncensored” models based on tags: https://huggingface.co/models?other=uncensored
We Never Truly Know How an LLM Has Been Trained 🤔
It’s important to note that we never really know how an LLM has been trained. Much like using software from vendors or open source libraries, we have to do our own due diligence to ensure that the model does or does not do the things we want it to do.
Even if we validate the model with tools like Garak, all we can do is increase our level of confidence and trust in the model, but the possibility of some form of corruption is never zero.
In fact, LLMs can have backdoors or other hidden features that we can’t see or know about!
Probably Need to Fine Tune Your Own Model 🛠️
In the end, if you want a “free range” model that you can trust most of the time, you will probably have to fine tune your own model, based on an existing open source model. This could be technically and economically challenging, but it’s probably the only way to get a model you can (mostly) trust. But fine tuning one on an existing model would be a lot less work than training one from scratch.
How To Fine Tune Your Own Model ❓
This is a topic for future posts!
Conclusion 🎉
Obviously this post is full of warnings and caveats, but that’s the nature of the LLM beast–these things can say and do terrible things if they don’t have the right guardrails. So a lot of what the big vendors are doing is trying to limit the damage that can be done with their models, which sometimes gets in the way of certain valid use cases. Our use case is an example of that.
Ultimately, LLMs are important tools, and we have to work on these tools to make sure they are as useful as possible for defenders. It’s not all doom and gloom, we just have to know what we are getting into, and, as cybersecurity practitioners, we absolutely MUST know how these tools can be broken.

